I predicted AI journalism 10 years ago - and I got it wrong
May 2025 • 15 min read
Almost ten years ago, I came into the tech industry in Nigeria at a fortunate time. There was a very strong sense of community, with a lot of early-phase builders working together. My good fortune was because platforms like TechCabal told the stories of these builders. The inspiration I got from these stories became the foundation for my career, and it was incredibly important that they were told.
As I consumed several articles, I was intrigued by what it took to write great stories and how software could help. I had an idea for a tool to generate stories for journalists based on strictly-defined prompts 1. After answering a couple of questions, you get a long-form story can be tweaked at will. If any of that sounds familiar, it’s because it has turned out to be a simple usecase for Generative AI.
I did not pursue the idea any further because a usable solution was not in my skillset at the time, and the technology wasn’t there. I also had no way of knowing that it would manifest in this way. In hindsight what I simply needed to do was invent the Transformer model 2 and co-found OpenAI, one of the most valuable companies in the world today.
Also, nobody reached out:
Hopefully i’ll be able to revisit this later in some machine-learning capacity. If you’re reading this and have ideas on how this could work, please reach out.
Thank you to Osarumen for supporting the original idea and encouraging me to pursue it further.
Generative story-telling is finally here. Now what?
Nowadays, I don’t believe we should aim to have machines fully generate our stories. Journalism is about much more than generating content, and Large-Language Models (LLMs) cannot be fully trusted with both real-time and historical facts. BBC research recently found that popular AI tools like ChatGPT and Gemini produced significant inaccuracies in over half of the news summaries that they tested 3.
It should not be surprising that I now think the best use of such a tool would be as an assistant for research, fact-checking, and ideation. LLMs should not replace our fundamental ability to reason and create.
So how can we use AI to write better stories in the real world?
Training a Model
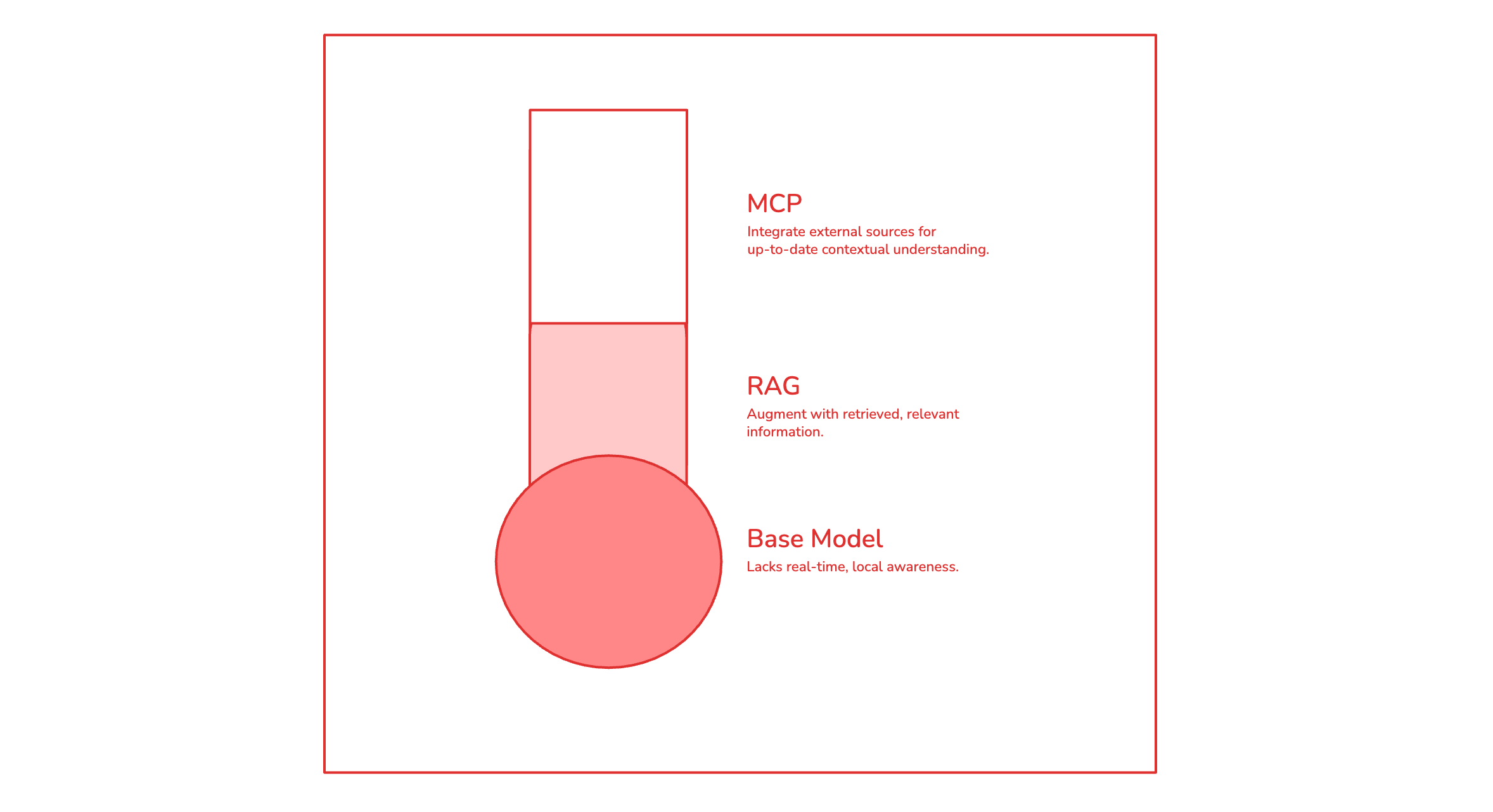
The foundation of any LLM is the underlying model. Most popular vendors have a vast amount of available models with different price points. There are also several open-source models of comparable quality 4. The models are trained on a vast amount of data, which helps them to generate and understand human language.
Because existing models are already so good at human language, there should be no need for a journalist/newsroom to train their own models. Training is expensive and it’s more cost-effective to use one of the existing models. The skill you should probably be honing is choosing the right model. Personally, I prefer the OpenAI models for any sort of creative writing/ideation.
The existence of AI doesn’t mean we should blindly apply it to everything, though. It’s important to be clear about why you are applying LLMs to story-telling. It’s not enough to use a shiny new technology just because it exists. There’s no need to replace one tool with another if it doesn’t provide any real benefit.
The answer to “why LLMs?” is best explored by understanding what they are good at. They are able to better handle non-deterministic scenarios where traditional systems fall short. They can evaluate context, consider different scenarios and spot patterns 5. Instead of a sequential, checklist-based approach, an LLM can take in structured/un-structured information and apply a holistic approach to solving a complex problem.
This strength makes LLM perfect for the world of journalism, which is full of unstructured data to be broken down, understood and used to create compelling stories. With the right approach, we can use AI tools to write more insightful stories.
Even though LLMs are trained on a vast database of information, it’s very likely that they don’t have local context, or that the training information is already out-of-date. This can cause them to hallucinate and provide answers that are out-of-context or just plain wrong.
There are two primary ways to provide context - Retrieval Augmented Generation (RAG) and more recently the Model Context Protocol (MCP).
If you’re not interested in an engineering approach and you want to consume existing tools instead, skip to the relevant sections below.
Retrieval Augmented Generation (RAG)
RAG is a method used to improve the output of an LLM by allowing it to reference external, authoritative knowledge before generating a response. With access to factual information, the model is less likely to “hallucinate” 3. This is especially important in a field like journalism where wrong information can spread like wildfire.
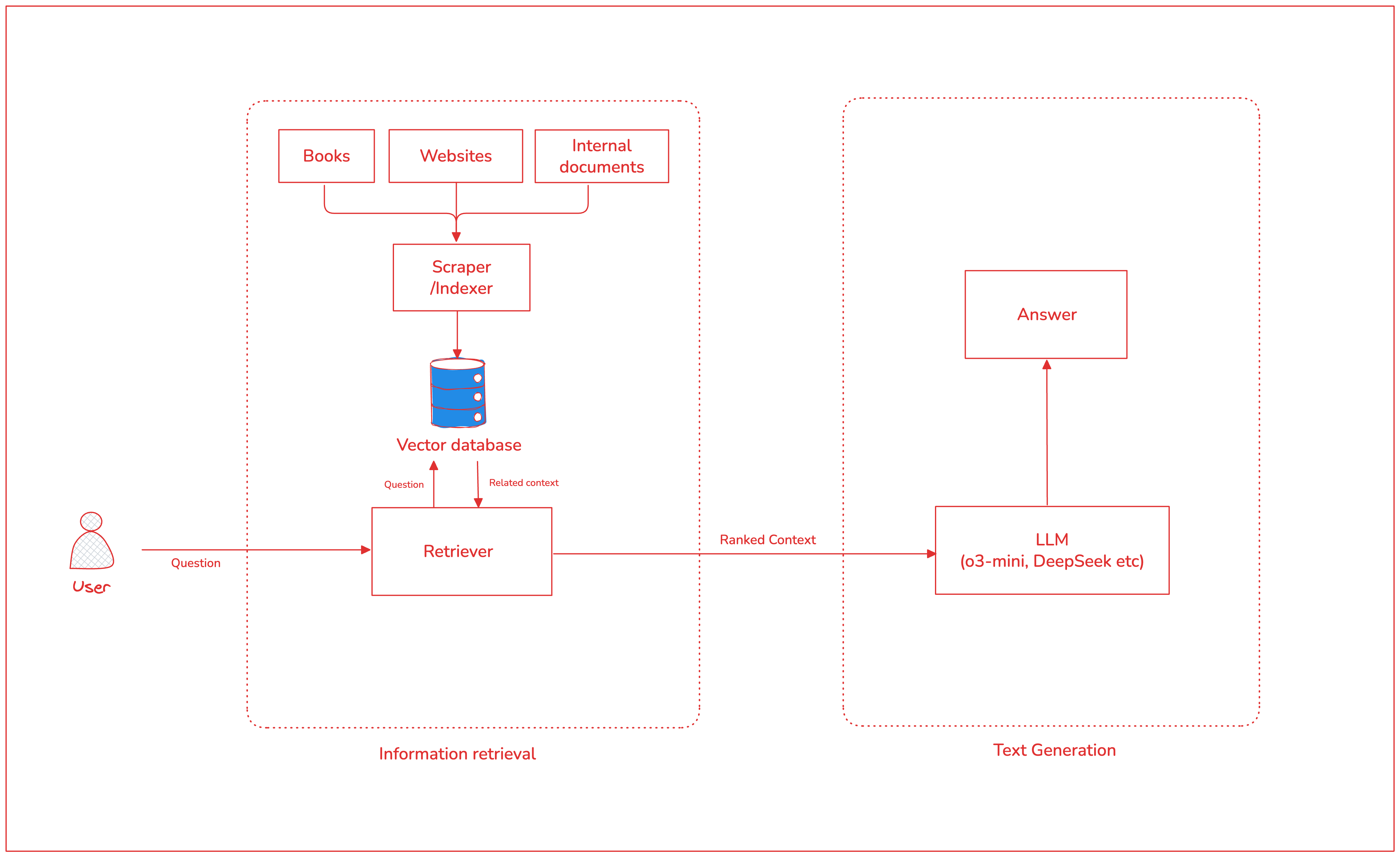
With RAG, an LLM assistant for journalism can first obtain relevant new information from websites, blogs, books, etc, for context-aware responses. While users of AI products like ChatGPT can simply instruct the LLM to “search the web”, a more powerful solution is to implement in-house RAG based on proprietary data and research.
A basic RAG system can be implemented as follows:
-
Ingest the data: Compile the information into an accessible source like a filesystem or database. For example, you can implement a basic web scraper or listen to RSS feeds. There are several options because LLM tools like LangChain can load several types of documents, from webpages and PDFs, to cloud providers.
-
Pre-process the data: To solve for context-window limitations, basic RAG splits text data into chunks. These are then used to create vector embeddings and stored in a vector database. When providing context to the LLMs, the same mechanism is used to do a similarity search between the user query and the stored data 6. This helps the LLM find the most relevant information.
from langchain.text_splitter import RecursiveCharacterTextSplitter def split_documents(self, documents): """Split documents into smaller chunks for better retrieval.""" text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200, length_function=len, ) chunks = text_splitter.split_documents(documents) print(f"Split into {len(chunks)} chunks") return chunks # Load all the documents into memory documents = load_documents() # Split documents into chunks chunks = split_documents(documents) -
Store the data in a vector database: Production-grade systems should store data in a database. But for test purposes, local storage is acceptable.
from langchain_community.embeddings import HuggingFaceEmbeddings from langchain_chroma import Chroma persist_dir = "./vectorstore" embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2") # Create and persist the vector store vector_store = Chroma.from_documents( documents=chunks, embedding=embeddings, persist_directory=persist_dir ) -
Prompt augmentation and response generation: When handling a query, the prompt provided to the LLM can then be enriched with the most relevant documents based on the basic semantic search.
def setup_qa_chain(self, vector_store: Chroma) -> RetrievalQA: """Set up the question-answering chain""" prompt_template = """You are an expert on African technology companies and startups. Use the following articles to answer the question. If you don't know or aren't sure, say so. Always cite your sources using the provided URLs. Articles: {context} Question: {question} Answer with facts from the provided articles, citing sources using URLs when possible:""" PROMPT = PromptTemplate(template=prompt_template, input_variables=["context", "question"]) # Create the chain qa_chain = RetrievalQA.from_chain_type( llm=OpenAI(temperature=0), chain_type="stuff", retriever=vector_store.as_retriever( search_type="similarity", search_kwargs={"k": 3} ), chain_type_kwargs={ "prompt": PROMPT, "verbose": True }, return_source_documents=True ) return qa_chain qa_chain = setup_qa_chain(vector_store) ## Answer a user's question result = qa_chain({"query": question})
I’d argue that while vector embeddings are useful and can help with making sense of a large corpus of unstructured data, it’s possible to do RAG by simply just augmenting prompts. If context windows don’t matter much and you have a limited set of specific data, you can just load the text into the prompt. That’s also a form of RAG, albeit very basic.
Full sample code can be found on Github.
Model Context Protocol (MCP)
MCP is a more recent development from Anthropic. Their aim was to define an industry standard for providing LLMs access to external resources 7. Similar to RAG, this saves LLMs from their isolation from data.
One problem with RAG is the need to implement an LLM integration for every data source. Instead, developers can create an MCP server for any MCP client application to consume.
We’ve already seen an explosion of MCP servers in the past couple of months, with several infrastructure companies also making it possible to host remote MCP servers. While the standard is nascent, it’s simple to implement with little barrier-to-entry. The main concern has been security, which has seen several proposals 8.
An MCP server for a news agency/website is a simple way to connect LLMs to the proprietary information. The server can provide (and describe) tools for the LLMs to get context in specific ways. i.e. instead of implementing RAG and adding context to the LLM prompt, you provide a server that tells the LLM how to do different things.
Here’s how a simple MCP server for a blog could look like:
from mcp.server import NotificationOptions, Server
import mcp.server.stdio
# Initialize the MCP server
#
# The Server classes poll the news sources and store
# the information in a local SQLite database.
#
# Each tool call made by the LLM is then simply a wrapper
# for an SQL query for post information.
#
app = Server("news-server")
news_server = NewsServer(
base_url="https://example-news-site.com",
rss_feeds=[
"https://example-news-site.com/rss",
"https://feeds.example-news.com/latest"
]
)
@app.list_tools()
async def handle_list_tools() -> list[types.Tool]:
"""List available tools for the LLM"""
return [
types.Tool(
name="get_article",
description="""
Fetch full article content from a URL.
COST OPTIMIZATION INSTRUCTIONS:
- Use 'get_article_summary' first to decide if full content is needed
- Full articles may contain 1000+ tokens - use sparingly
- Cache is utilized automatically to reduce redundant fetches
""",
inputSchema={
"type": "object",
"properties": {
"url": {
"type": "string",
"description": "Full URL of the article to fetch"
}
},
"required": ["url"]
}
),
]
async def main():
# Run the server using stdin/stdout streams
async with mcp.server.stdio.stdio_server() as (read_stream, write_stream):
await app.run(
read_stream,
write_stream,
InitializationOptions(
server_name="news-server",
server_version="0.1.0",
capabilities=app.get_capabilities(
notification_options=NotificationOptions(),
experimental_capabilities={},
),
),
)
if __name__ == "__main__":
import atexit
atexit.register(lambda: asyncio.run(cleanup()))
asyncio.run(main())
While MCP is a refreshing way to provide context to LLMs, it’s not an automatic shortcut to escape the challenges of RAG. The data ingestion and indexing requirements remain - you still need the data stored somewhere before it can be exposed. It’s also likely that you need real-time information, which becomes even more of a challenge.
An LLM-powered news pipeline?
For any of this to be relevant to the industry, it needs to actually work in practice. A great way to get an edge on other news agencies is to create a structured data pipeline that can be combined with the power of LLMs, alongside existing best practices.
LLMs can improve several workstreams as assistants:
- Summarisation: During research, you can get an LLM to summarise streams of verbose documents.
- Script ideation: Instead of blindly generating stories, you can get new ideas and iterate on existing ones.
- Fact-checking: With access to both your internal tools and several external sources, LLMs can support and scale up fact-checking during the writing process.
- Content personalisation: You can rewrite existing posts to tailor to specific audiences, or even translate posts to other languages while maintaining the original tone.
- General research: Ask questions, get answers quickly.
The pipeline itself will differ based on company/agency/industry goals, and the scale of the technical team. You can however consider the following basic framework for an internal pipeline.
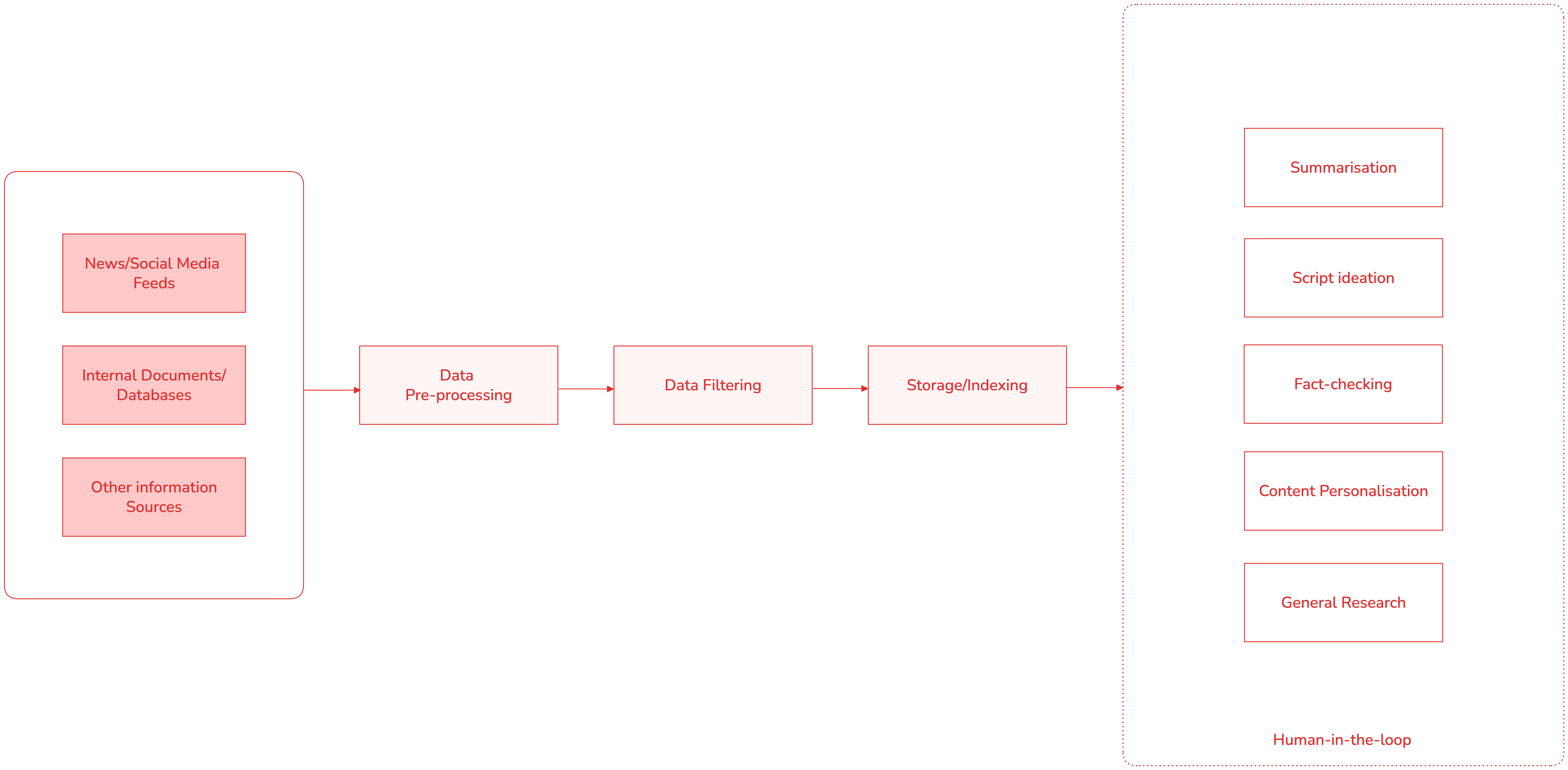
#1: Ingest, index and store information
The data ingestion layer can collect information from several sources - third-party news feeds (APIs), social media feeds, and internal documents/databases. Collection can be implemented using long-polling or by listening to webhooks for new updates. Each incoming item can then be normalised into a common format and pre-processed.
Pre-processing is necessary to clean up unwanted information like HTML tags (if scraping other websites), or remove duplicates/irrelevant items. Depending on the scale, ingestion can be implemented using stream processing (e.g. Airflow, AWS Kinesis) or just simple batch jobs.
After processing and filtering, the data can then be stored in an in-house database/content repository. To help with effective RAG, it would also be useful to index the data in a vector database. This knowledge index can then be exposed to LLMs using RAG techniques shown in the examples above.
#2: Use the information: Human in-the-loop techniques
When building automation, not enough people consider the main point - it’s there to help humans. You can become more productive if you consistently prioritise how the automation works hand-in-hand with humans.
In the context of LLMs, always consider their strengths and how powerful they are, but also their downsides. Some common downsides are hallucination, and misunderstanding given tasks. The former can be improved using the context-enrichment techniques we’ve discussed, and the latter with better prompting.
It’s however still possible for LLMs to get things wrong. This is why you should always design with human-in-the-loop in mind. For each of the workstream examples, a human should always cross-check and act as a judge of the data produced by an LLM. This isn’t much different from working with an intern or assistant.
An editor can review an LLM-generated summary to check what sources were used, and flag any claims. Research assistants can provide feedback to LLMs about the accuracy and quality of generated content. Instead of just one draft of an article, an LLM can be used to generate 2-3 drafts to be ranked during team collaborative sessions.
As a senior employee, you should encourage these techniques instead of looking to replace humans with LLMs blindly. Your reward is most likely a more efficient organisation that can hit greater goals than initially planned.
#3: Guardrails
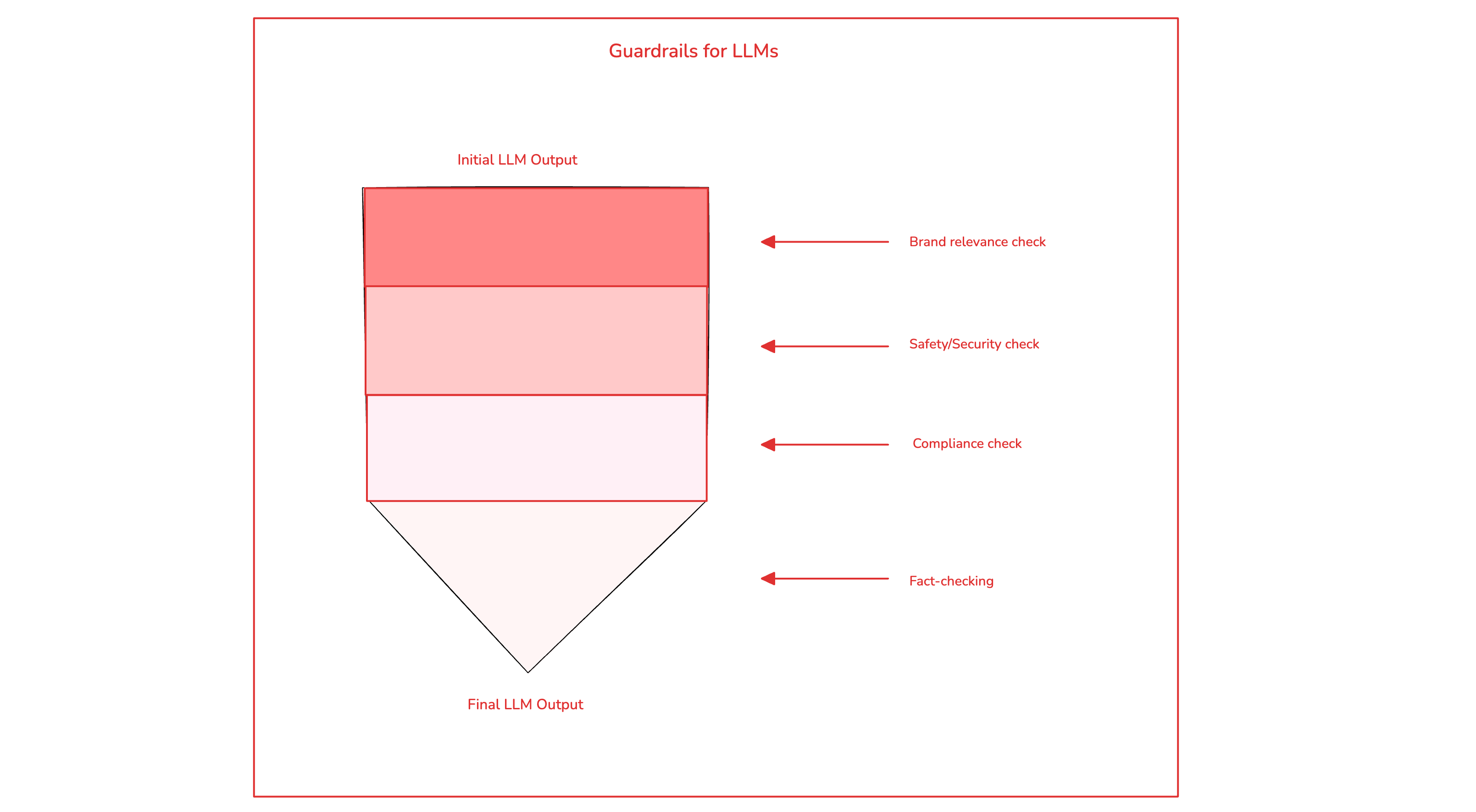
Another way to ensure that LLMs behave the way you want is to implement guardrails. Well-designed guardrails will help you to manage risk, navigate compliance, ensure safety and even protect against security breaches.
You can think of guardrails as a layered defense mechanism 5. As a journalist, the easiest way to get started with guardrails is to replicate the checks you’d normally make. For example, if there are certain brand guidelines for every article, a guardrail can be used to make sure LLMs do not deviate from that. This can be referred to as a brand-relevance classifier.
Another example of a guardrail could be to ensure safety and security. You can guard against common software security attacks by preventing SQL injection, jailbreaks or prompt injections. While it is unlikely that an LLM produces malicious output, you should always aim to be protected against worst-case scenarios.
If there are certain types of content that are out-of-bounds for your brand such as political satire or propaganda, a content-moderation classifier can be added org-wide to decrease risk and save human time. It also wouldn’t hurt to have a fact-checking classifier to confirm that LLM output is accurate and reduce the changes that human fact-checkers need to make.
As your usage of LLMs evolves, you can continue to tweak the guardrails to reflect your current goals.
Looking back at our example in RAG, we can add a guardrail to prevent propaganda. We simply create a new chain that has our safety principles added.
from langchain.chains import ConstitutionalChain
# Define safety principles
safety_principles = [
ConstitutionalPrinciple(
name="No Propaganda",
critique_request="Does this output contain political propaganda?",
revision_request="Rewrite to remove the propaganda"
),
]
safe_qa_chain = ConstitutionalChain.from_llm(
# Existing QA Chain with RAG enabled
chain=qa_chain,
constitutional_principles=safety_principles,
llm=llm
)
result = safe_qa_chain("Tell me about TechCabal")
Existing Tools: AutoRAG
If you need a quick and simple way to add get an LLM assistant for any existing content, AutoRAG might interest you 9. You can use AutoRAG - a Cloudflare product - to build a simple chatbot that can answer questions about a website. Disclaimer: Cloudflare is my current employer.
Teams would typically use this to help customers get answers to product questions or navigate documentation, but I can see how it can easily apply to writing as well.
Instead of building a complicated RAG system that brings maintenance costs, you can use AutoRAG to provide research, fact-checking and summary assistants to your team members. This is an easy way to get introduced to the world of LLMs, and it’s available on the free plan as well.
Personally, I plan to experiment with implementing AutoRAG for my personal website. It can help answer questions about me and my career for anyone that just wants to skim. It can also be a useful tool to help a journalist quickly get information about a company from their website without relying on search-engine indexing.
A new industry-standard addition to press kits, perhaps? For more information about AutoRAG, see the demo on Youtube.
Other Existing Tools
There are several other ways to get more productive using LLMs without engineering firepower. These are some of the tools that I find helpful today:
-
ChatGPT: I use ChatGPT for general daily questions, but it’s also my most-used tool for scripting and ideation. I find that it’s better at the “creative” aspects than other tools. My favourite feature however, is Deep Research. I enjoy getting in-depth reports about niche subjects from various sources. For example, it can look at research papers, which enhances the authenticity of any ideation. The obvious challenge with using a consumer product is the lack of context, but with the rise of MCP servers, I won’t be surprised if more people create servers and connect their resources to ChatGPT directly. Direct integration obviously comes with a risk of data infringement/safety, but it depends on you and your risk appetite.
-
Gemini: My primary use for Gemini is Deep Research. While I prefer the output and depth of ChatGPT DR responses, it can take a long time to produce a result. This can be frustrating when have a lot of tasks to do. Gemini is also very thorough. A bit too verbose for my liking, but thorough. It’s also the more affordable option and you get more value (and executions) for your money.
-
NotebookLM: I was blown away the first time I used NotebookLM to analyse a document I uploaded. It’s a great way to do single-instance RAG and by extension, useful for ideation and research. I haven’t used it extensively in a while, but it’s a tool you should definitely be looking at to improve your research workflow 10.
-
Elicit: I enjoy using Elicit for research because it’s a great way to find research papers relevant to any topic, using plaintext queries. A similar niche tool to find resources relevant to journalism would be great, but if you ever need to find papers, I recommend. Imagine if you could find old newspapers that reference a topic you are writing about on the fly? Someone speak to Ridwan from archivi.ng.
-
Napkin AI: Napkin is great for getting sketches based on your text. I use it to get rough ideas for diagrams, especially when I’m struggling to visualise a thought 11.
What next?
For people familiar with the advancements in AI, I don’t expect most of the tools/ideas mentioned in this post to be particularly new. I’ve been hoping to find more use-cases for LLMs other than assistants, but I think we are still just scratching the surface there.
I plan to continue watching this space, and I’m open to conversations/ideas. It would also be interesting to turn some of these ideas into a research paper, so that’s coming up next. If you’re in academia and want to chat/get a coffee, please reach out. I’ll also implement a basic RAG for this blog, so you can ask an LLM to write like me and be amazed at my brilliance.
Until next time.
Footnotes
To help me grow on Youtube and learn about Monitoring, Machine Learning, and SRE, please subscribe here.
And to get notifiied about new posts, please subscribe here.